Colombia’s data centre market is expanding at a remarkable pace, fuelled by the rise of artificial intelligence (AI). As of 2025, the country hosts 38 data centres — 29 in Bogotá, 4 in Medellín, 3 in Cali, and 2 in Barranquilla — with several more on under development. Valued at US$442 million in 2024, the sector is expected to nearly triple to US$1.16 billion by 2030, growing at an annual rate of 17.6%.
This boom promises major opportunities in digital infrastructure and foreign investment. Yet it also brings serious sustainability challenges. Data centres are notoriously resource-intensive, consuming vast amounts of water for cooling and electricity to keep servers running.
Recognising both the potential and the risks, the Colombian government launched a US$111.5 million National AI Policyin February 2025. The plan seeks to decentralise data centre infrastructure and promote hyperscale facilities powered by renewable energy and water-efficient technologies.
The pressing challenge now is ensuring that Colombia’s AI-driven data centre boom drives inclusive economic growth while safeguarding the country’s water and energy resources.
Projected Impacts
Water Stress
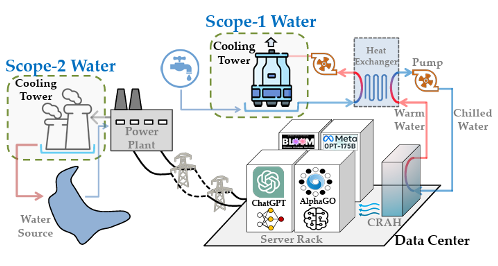
AI’s rapid growth comes with a heavy water footprint. Globally, meeting demand for AI could require up to 6.6 billion cubic meters of water withdrawals by 2027. Data centre water consumption is driven by cooling (Scope 1), electricity usage (Scope 2), and hardware manufacturing (Scope 3).
To address environmental concerns, some providers are experimenting with air-cooling systems that reduce direct water withdrawals. However, these systems are often more energy-intensive, which can increase Scope 2 water use. The lack of reliable data on Scope 3 impacts further complicates assessments, highlighting the need for more transparent and comprehensive reporting.
Example of a data centre’s operational (scope 1+2) water usage
Source: Li et al. (2025)
Colombia faces particular risks. New data centres are planned in hot regions such as Santa Marta, where cooling demands will be especially high. Even Bogotá, with its milder climate, faces serious water availability concerns. Between 2023 and 2024, the city experienced once of its worst droughts on record, with its reservoir levels falling to just 10.5%.
Adding to the challenge, Colombia is already one of the world’s top consumers of water per capita, using nearly three times the OECD average. This is partly driven by industrial users facing some of the lowest water tariffs in the region. In 2023, Coca-Cola reportedly paid just US$2,605 to extract 64 million litres near Bogotá. At US$0.008 per cubic meter, Colombia’s industrial water tariff is a fraction of Mexico’s (US$0.99) or Brazil’s (US$0.036).
Colombia’s governance framework is not keeping up with these mounting pressures. An evaluation of the National Policy for Integrated Water Resources Management (2010–2022) found that the country lacks adequate data on water demand, while Bogotá’s District Water Plan, due for an update in 2021, has yet to be revised. Both national and local policies urgently need updating to integrate future water use projections tied to data centre growth.
Without stronger governance and more realistic tariffs, water scarcity could not only constrain Colombia’s AI-driven data centre industry but also threaten access to clean water for communities, exacerbating social and environmental stresses across the country.
Energy use
AI is driving a sharp rise in data centres’ energy needs. While traditional facilities consume between 10 and 25 megawatts (MW) annually, hyperscale AI-focused centres can exceed 100 MW — the equivalent of powering 100,000 households. Because these facilities often cluster in specific cities, their concentrated demand puts major stress on local power grids.
To manage both energy security and carbon footprints, many operators are investing in renewable sources. These projects can accelerate growth in the clean energy sector, but much of the power produced is consumed by the centres themselves, limiting the amount of renewable energy available to the wider grid.
Colombia’s relatively clean electricity mix has helped attract investment. In 2023, 64.4% of power came from hydropower, while 31.8% came from fossil fuels, and only 1.2% from solar and wind. The country’s heavy reliance on dams, however, leaves the system vulnerable. Recent droughts forced greater use of fossil fuels to meet demand, undercutting Colombia’s climate goals. Without a rapid scale-up of solar and wind capacity, rising demand from data centres risks locking the country into deeper dependence on fossil energy, with consequences for both emissions targets and long-term energy security.
Electricity generation sources in Colombia, 2023
Press enter or click to view image in full size
Source: IEA (2023)
Over the past three decades, Colombia has modernised its energy sector and welcomed private investment, spurring diversification and infrastructure growth. Still, persistent barriers remain. There are gaps in transmission capacity, delays in environmental licensing, and strong community opposition to new projects. Unless these challenges are resolved, Colombia will struggle to expand renewable energy fast enough to keep pace with the demands of an AI-driven data centre boom.
Case Studies
Because data on Colombia’s data centre impacts remains limited, it is useful to look at two regional leaders, Mexico and Chile, where the sector is more mature. Both cases offer valuable lessons for Colombia as it expands its own market.
Mexico
Mexico’s data centre market is projected to reach US$2.26 billion by 2030, growing at an annual rate of 13.5%. The country already hosts 59 centres, with nearly a third concentrated in Querétaro. Tech companies have pledged thousands of jobs and billions in investments, but these promises come with serious environmental trade-offs.
Querétaro is one of Mexico’s most drought-prone states. Yet industrial water use there skyrocketed from 4% of total consumption in 2003 to 40% by 2018. The surge has fuelled protests from indigenous and rural communities, driven up water costs for residents, and left local reservoirs under severe stress. In April 2025, two of the state’s seven reservoirs were completely dry, and overall capacity dropped to just 32.5%. Energy shortages have compounded the crisis, with frequent power outages as the regional grid struggles to keep up with rising demand.
Despite these risks, investment continues. In January 2025, Amazon Web Services announced a US$5 billion investment in Querétaro to serve all of Latin America. Mexico does have a sustainability norm for data centres introduced in 2014 (NMX-489), but because compliance is voluntary, its impact has been limited.
Querétaro’s experience underscores a key warning for Colombia. Without proactive water and energy management, rapid data centre growth can quickly outpace local resources and spark social unrest.
Planned data centre investments in Mexican states under drought.
Source: Menski et al. (2024)
Chile
Chile’s data centre market is projected to hit US$1.24 billion by 2030, growing at a CAGR of 8.27%. The country currently has 62 centres, 55 of them clustered in Santiago. But Chile is also one of the world’s most water-stressed nations, and public opposition has been strong.
In 2024, Google was forced to suspend a planned US$200 million data centre in Santiago after citizen mobilisation and a partial court reversal of its environmental permits. The company later committed to redesigning the project with stricter sustainability standards and more water-efficient technologies.
To address these challenges, Chile recently launched its National Data Centre Plan (2024–2030), developed through multi-stakeholder consultations. The plan includes a digital tool to guide sustainable site selection, a multi-stakeholder monitoring committee, streamlined permitting processes, and public–private clean production agreements to boost efficiency. It also encourages the creation of AI campuses in regions with abundant renewable energy resources, reducing pressure on water-stressed areas like Santiago.
Chile’s proactive approach highlights the importance of early planning, strong stakeholder engagement, and enforceable sustainability standards; lessons Colombia can apply before its own boom accelerates further. That said, it remains to be seen how effectively the plan will be implemented in practice and whether it can truly balance data centre growth with water and energy sustainability.
Policy Recommendations
Colombia is not yet fully prepared to manage the environmental impacts of rapid data centre expansion. To address this challenge, the following recommendations draw on Professor Mariana Mazzucato’s Entrepreneurial State framework. Unlike traditional models that view the state as a passive actor intervening only after market failures occur, this approach positions the state as a proactive market-shaper capable of driving more inclusive and sustainable outcomes.
The framework rests on four core principles: setting a clear direction for change; building the capabilities necessary to drive that change, including sectoral knowledge, risk-taking, and patient finance; adopting dynamic metrics that capture long-term and spillover effects; and ensuring the equitable sharing of both risks and rewards. The recommendations below are structured around these principles.
Set a Direction
Colombia’s National AI Policy sets a strategic direction by tasking the Ministry of Science, Technology, and Innovation with designing and implementing, between 2025 and 2026, a mechanism to accelerate data centre development with a focus on renewable energy and water-efficient technologies. To turn this vision into reality, the government should:
1. Urgently update water management plans at the national and city levels, particularly in areas expecting new facilities. Plans should integrate real-time data on water supply and demand to guide sustainable growth.
2. Embed environmental conditionalities in licensing and public procurement. These include requiring data centre developers to submit detailed technical specifications and projections for water and energy use and mandating the use of resource-efficient technologies accounting for the full spectrum of water use (Scope 1, 2, and 3).
Build Capabilities
To effectively manage data centre expansion and ensure environmental risks are mitigated, the government should invest in developing local expertise and infrastructure. This means not only regulating the sector but also equipping public institutions with the necessary knowledge and resources. To achieve this, the government should:
3. Strengthen public sector expertise by employing AI and data centre specialists, ensuring government agencies have the necessary knowledge to make informed decisions and effectively evaluate the technical information provided by data centre operators.
4. Establish co-investment mechanisms that leverage public, private, and multilateral funding to expand renewable energies and improve water management systems. This funding should be directed not only towards meeting data centre needs, but also to covering the water and energy requirements of low-income households.
5. Support national research and innovation to develop and test solutions for energy and water efficiency. This aligns with Action 3.1 of the National AI Policy, which funds AI-related R&D projects led by universities, research institutions, and private-sector partners.
Use Dynamic Metrics
To effectively manage the impact of data centres, it is essential to move beyond static metrics and ensure real-time data is continuously available. This will enable more responsive and effective resource management, especially during emergencies. To this end, the government should:
6. Install smart meters in data centres to provide real-time water and energy data to authorities. These data streams can feed into AI-powered tools for land use and resource planning that will be developed under Action 6.12 of the National AI Policy.
7. Develop a comprehensive monitoring and evaluation framework that tracks not only economic returns, but also spillover environmental and social impacts.
Share the Risks and the Rewards
With many data centre operators in Colombia being foreign owned, there is a risk that the sector could perpetuate an extractive model, whereby multinationals extract wealth and resources while the government and local communities bear the brunt of the environmental and social costs. To equitably share both the risks and the rewards of the data centre market, the government should:
8. Urgently increase industrial water prices to better reflect the true costs of water and the externalities its extraction imposes on the environment. Energy prices should also be adjusted to more accurately account for Scope 2 water consumption. The water and energy tariffs for data centre providers and other high-water use industries should remain flexible throughout the year, with the option to increase them during periods of water scarcity. This will help regulate demand while encouraging more efficient water use.
9. Integrate conditionalities in the licensing processes for data centres and related renewable energy projects, requiring a small percentage of their computing and energy capacity be reserved at a reduced cost for use by Colombian universities, research institutions, and private sector partners working on environmental projects.
10. Pilot geographical load balancing, distributing AI workloads across data centres based on regional water and energy availability, reducing pressure during emergencies.
These recommendations carry both risks and costs that must be carefully managed. One concern is a potential slowdown in Colombia’s data centre market. However, this does not mean halting growth. As noted, Chile’s market is expanding at an annual rate of 8.27%, while Colombia’s is growing at 17.6%. A modest slowdown is a reasonable trade-off if it ensures growth that is both sustainable and inclusive.
Another challenge is potential pushback from data centre operators who may resist stricter regulations or engage in lobbying. Yet Colombia holds a strong comparative advantage. The cost of building a data centre in Bogotá costs just US$7.10 per watt, compared with São Paulo (US$10.10), Querétaro (US$10.00), and Santiago (US$8.30). This gives the country room to implement higher standards without losing competitiveness. As Chile’s experience shows, clear environmental regulations can even encourage companies to adopt more efficient technologies.
From a financial perspective, while a detailed analysis is still needed, these recommendations appear economically advantageous. The government has already allocated US$111.5 million for the National AI Policy, which can support research, capacity building, and monitoring. Additional revenue from higher tariffs and licensing can be invested in strengthening water and energy infrastructure, while long-term environmental costs can be mitigated through effective conditionalities.
Conclusion
Colombia’s AI-driven data centre boom presents significant opportunities for digital growth, investment, and job creation. However, these benefits could be undermined without careful management of water and energy resources. The National AI Policy provides a strong foundation, but its success will depend on the state embracing an entrepreneurial role: setting a clear strategic direction, building the necessary capabilities, adopting dynamic metrics, and ensuring that risks and rewards are shared equitably.
If implemented effectively, Colombia can become a regional leader in developing a digital economy that is fast-growing, sustainable, and inclusive. Conversely, failure to act could provoke strong community opposition, as local water and energy resources may be perceived as being diverted to foreign-owned facilities. Transparent public engagement will be essential to build trust and demonstrate that policies protect both people and ecosystems.
Beyond water and energy, data centres also create other environmental and social pressures, including increased demand for critical minerals, greenhouse gas emissions, e-waste generation, and land-use competition. While these fall outside the scope of this blog, they merit further analysis to fully understand AI’s environmental impact in Colombia.
This paper is an adaptation of a paper submitted on 8 May 2025 for Latin American Economics (AMER0017), an elective course of IIPP’s MPA in Innovation, Public Policy, and Public Value.
Madison Chock and Evan Bates started the 2025-26 figure skating Grand Prix season the same way as they ended the last two two – at the top of the rankings.
Skating to a collection of Lenny Kravitz hits, the USA ice dance couple took the lead…
The final piece of China’s cross-border data transfer framework has now been released with the issuance of the Certification Measures. Effective January 1, 2026, businesses must closely monitor certification institutions, standards, and application procedures. Early preparation and strategic planning will be essential for long-term compliance and risk management.
On October 14, 2025, the Cyberspace Administration of China (CAC) and the State Administration for Market Regulation (SAMR) jointly issued the long-awaited Measures for Certification of Cross-Border Personal Information Transfer (hereinafter referred to as the “Measures”), which will officially take effect on January 1, 2026.
The release of the Measures marks a pivotal moment in China’s data governance landscape. It completes the three-pathway framework for cross-border personal information transfers established under the Personal Information Protection Law (PIPL).
Find Business Support
With the certification method now fully defined, China’s regulatory architecture for cross-border data transfer (CBDT) is considered comprehensive and operational.
The Measures clarify key aspects of the certification process, including scope and applicability, application procedures, certification body obligations, as well as supervision and enforcement.
This final regulatory piece enhances legal certainty for businesses. It offers enterprises another structured compliance pathway and may prove especially beneficial for multinational corporations engaged in frequent or large-scale data transfers.
Explore vital economic, geographic, and regulatory insights for business investors, managers, or expats to navigate China’s business landscape. Our Online Business Guides offer explainer articles, news, useful tools, and videos from on-the-ground advisors who contribute to the Doing Business in China knowledge.
Start exploring
Certification in China’s CBDT framework
Under Article 38 of PIPL, personal information processors in China who need to transfer personal data overseas for business or operational purposes must choose one of three legally prescribed pathways:
Undergo a security assessment organized by the CAC, except where exempted by relevant laws and regulations.
Undergo a certification for cross-border personal information (PI) transfer by a professional institution in accordance with the regulations of the CAC.
Sign a standard contract with a foreign party stipulating the rights and obligations of each party in accordance with standards set by the CAC.
Meet other conditions set by the CAC or relevant laws and regulations.
Since 2022, China has gradually built out this framework through a series of regulatory instruments. The Security Assessment Measures, released in July 2022, laid out detailed procedures for high-risk data transfers. In February 2023, the Standard Contract Measures were issued and came into effect in June, providing a more accessible compliance route for many businesses.
Find Business Support
However, the certification pathway remained incomplete for some time. While several technical standards and guidelines were released – such as the Security Certification Specifications for Cross-Border Processing of Personal Information V2.0 (December 2022) and the Information Security Technology – Certification Requirements for Cross-Border Transmission of Personal Information (March 2023) – a formal regulatory document was still missing.
Now with the release of the Measures, this long-awaited document provides the legal and procedural foundation for certification, aligning with earlier standards and the CAC’s January 2025 draft for public consultation.
Moreover, China’s State Administration for Market Regulation (SAMR) and Standardization Administration of China (SAC) jointly released the Data security technology—Security certification requirements for cross-border processing activity of personal information (GB/T 46068-2025), which will take effect on March 1, 2026.
All these developments signal that the three pathways for CBDT under the PIPL are now fully operational, marking a significant milestone in China’s data governance regime.
Applying for a certification for CBDT
The newly released Measures for Certification of Cross-Border Personal Information Transfer outline the specific conditions under which personal information processors may opt for the certification pathway to legally transfer personal data overseas.
Scope of application
To be eligible for certification, a personal information processor must meet all of the following criteria:
It is not a critical information infrastructure operator (CIIO)
Transfer volume thresholds:
Since January 1 of the current year, it has transferred the PI of between 100,000 people and one million people out of China (excluding sensitive PI).
Since January 1 of the current year, it has transferred the “sensitive” PI of less than 10,000 people out of China.
The data being transferred must not include important data as defined by Chinese regulations.
Importantly, the Measures prohibit data volume splitting or other circumvention tactics to avoid the security assessment requirement. If the data transfer volume exceeds the thresholds for certification, the processor must undergo a security assessment instead.
Pre-application obligations
Before applying for certification, personal information processors must fulfill several legal obligations, including:
The PIPIA must evaluate:
The legitimacy, necessity, and scope of data processing by both the processor and the overseas recipient;
The volume, sensitivity, and type of data being transferred, and potential risks to national security, public interest, or individual rights;
The technical and organizational safeguards promised by the overseas recipient;
The risk of data breaches or misuse, and the effectiveness of redress mechanisms;
The legal environment of the recipient’s jurisdiction and its impact on data protection; and
Any other factors that may affect the security of the data transfer.
The PIPIA report should be retained for at least three years.
Also read: How to Conduct a Personal Information Protection Impact Assessment in China
Application process
Processors must apply for certification through a professional certification institution authorized to conduct personal information protection audits. For overseas processors, the application must be submitted via a designated domestic representative or entity.
Once the application is approved, the institution will issue a certificate, valid for three years. To maintain continuity, processors must reapply six months before the certificate expires.
Supervision and enforcement
The Measures establish a multi-layered oversight mechanism:
National and provincial CAC and market regulation authorities will conduct regular and ad hoc inspections of certification activities and outcomes.
If certified processors are found to pose significant risks or experience data security incidents, authorities may initiate interviews and require corrective actions.
Whistleblowers, including organizations and individuals, may report violations to certification bodies or regulators.
Violations of the Measures may result in penalties under the PIPL, Cybersecurity Law, and Certification and Accreditation Regulations, and may lead to criminal liability where applicable.
Comparing standard contract vs. certification
Under China’s CBDT mechanisms, both the standard contract and certification pathways provide legal mechanisms for cross-border transfers of personal information. While they share many similarities, such as overlapping applicability and similar pre-transfer obligations, their structural differences make them suitable for distinct business scenarios.
The standard contract is a self-managed process in which enterprises sign a fixed-format agreement with the overseas recipient, strictly following the CAC’s template. After conducting a self-assessment, the enterprise submits the contract and related materials for filing with the provincial CAC, which may conduct formal or substantive reviews. As a commercial agreement, the standard contract is not publicly disclosed, and its contents are not subject to public scrutiny or external evaluation.
In contrast, certification is conducted by third-party professional institutions based on CAC-issued rules. It involves a comprehensive review of the enterprise’s technical, organizational, and governance measures. Unlike the standard contract, certification carries a degree of public authority – it reflects, to some extent, administrative recognition of the enterprise’s data protection capabilities. For companies with high reputational stakes in personal information protection, certification offers a credible external endorsement of their compliance posture.
Find Business Support
The compliance focus also differs. The standard contract emphasizes the legal obligations of a specific data transfer, ensuring the overseas recipient agrees to uphold data subject rights and assumes clear data protection responsibilities. Certification, on the other hand, assesses the enterprise’s overall compliance framework, including internal governance, data protection systems, and technical safeguards. It promotes ongoing compliance and dynamic supervision. In practice, the standard contract is more suited to “one-off” or occasional transfers, while certification is better aligned with enterprises engaged in frequent or long-term cross-border data activities.
Post-transfer supervision further distinguishes the two. With the standard contract, enterprises are responsible for monitoring the overseas recipient’s compliance, and CAC oversight is primarily conducted through the filing system. Certification bodies, however, implement continuous monitoring mechanisms. Certificates may be suspended or revoked, and violations are publicly disclosed, creating external compliance pressure.
Given these differences, the standard contract is generally more appropriate for low-volume, low-risk transfers. It is relatively easy to implement but offers limited flexibility due to its fixed format. Certification, by contrast, is better suited for enterprises with frequent, high-risk, or high-profile data transfers, or those seeking to demonstrate a high level of data protection. The certification is valid for three years, helping reduce repetitive compliance efforts.
Enterprises should assess their business scale, data export scenarios, and compliance capacity to select the most appropriate pathway for CBDT.
Aspect
Standard Contract
Certification
Legal nature and review mechanism
Enterprises sign a fixed-format agreement with the overseas recipient, following CAC’s template.
Self-assessment and filing with provincial CAC; subject to formal or substantive review.
Conducted by third-party institutions under CAC rules. Reviews technical, organizational, and governance measures. Carries independent credibility.
Compliance focus and depth
Focuses on contractual obligations. Ensures overseas recipient upholds data subject rights and assumes data protection responsibilities.
Evaluates full compliance framework, including governance, systems, and safeguards.
Emphasizes ongoing and dynamic compliance.
Post-transfer supervision and accountability
Enterprises monitor recipients’ compliance. CAC oversight via the filing system.
Certification bodies provide continuous monitoring (e.g., annual inspection). Certificates may be suspended or revoked; violations are publicly disclosed.
Applicability and flexibility
Best for low-volume, low-risk transfers. Easy to implement, but limited flexibility due to fixed format.
Suited for frequent or high-risk transfers. Valid for three years, reducing repetitive compliance.
Cost
Self-declaration will not incur any cost
The certification body will charge relevant fees.
What to watch next?
As the Measuresprepare to take effect on January 1, 2026, enterprises should go beyond understanding the basic provisions and actively monitor several key developments to ensure compliant and efficient implementation.
Key areas to monitor include:
Certification institutions and qualifications: Certification must be conducted by professional institutions that have obtained official qualifications for personal information protection certification. While the list of authorized institutions has not yet been released, it is expected to be jointly determined by the SAMR and CAC.
Certification standards and technical specifications: The Measures indicate that the CAC, together with relevant data governance authorities, will formulate detailed certification standards and technical specifications, while the market regulation authorities will define certification rules, certificate formats, and usage guidelines.
Application procedures and operational details: While the Measures outline the general process, many practical details remain to be clarified or will be defined by certification institutions, such as required documentation beyond the PIPIA report (such as data inventory, agreements, internal governance policies), online/offline application channels, review timelines and feedback mechanisms, proof of compliance capability for overseas recipients, and so on.
Companies are suggested to consult the official websites of the CAC, SAMR, and the Certification and Accreditation Administration of China (CNCA) for timely updates and implementation guidance.
Key takeaway
Personal information protection certification is a critical mechanism for enabling compliant, trustworthy, and internationally aligned data flows. As the Measures enter into force in 2026, enterprises must pay close attention to the qualifications of certification institutions, evolving standards and procedures, and long-term compliance obligations. For legal, compliance, and information security professionals, now is the time to study regulatory trends, plan ahead, and strengthen internal capabilities to ensure a smooth transition into the new regime.
If you need further interpretation or practical support, our team at Dezan Shira & Associates is here to assist you with tailored guidance and hands-on expertise. For more information, please get in touch with China@dezshira.com.
Deep inside a Swiss mountain, a group of students spent some of the summer simulating what life might be like inside a lunar base. The BBC joined them before the “mission”.
What was your childhood dream? For some, it was the idea of becoming an…
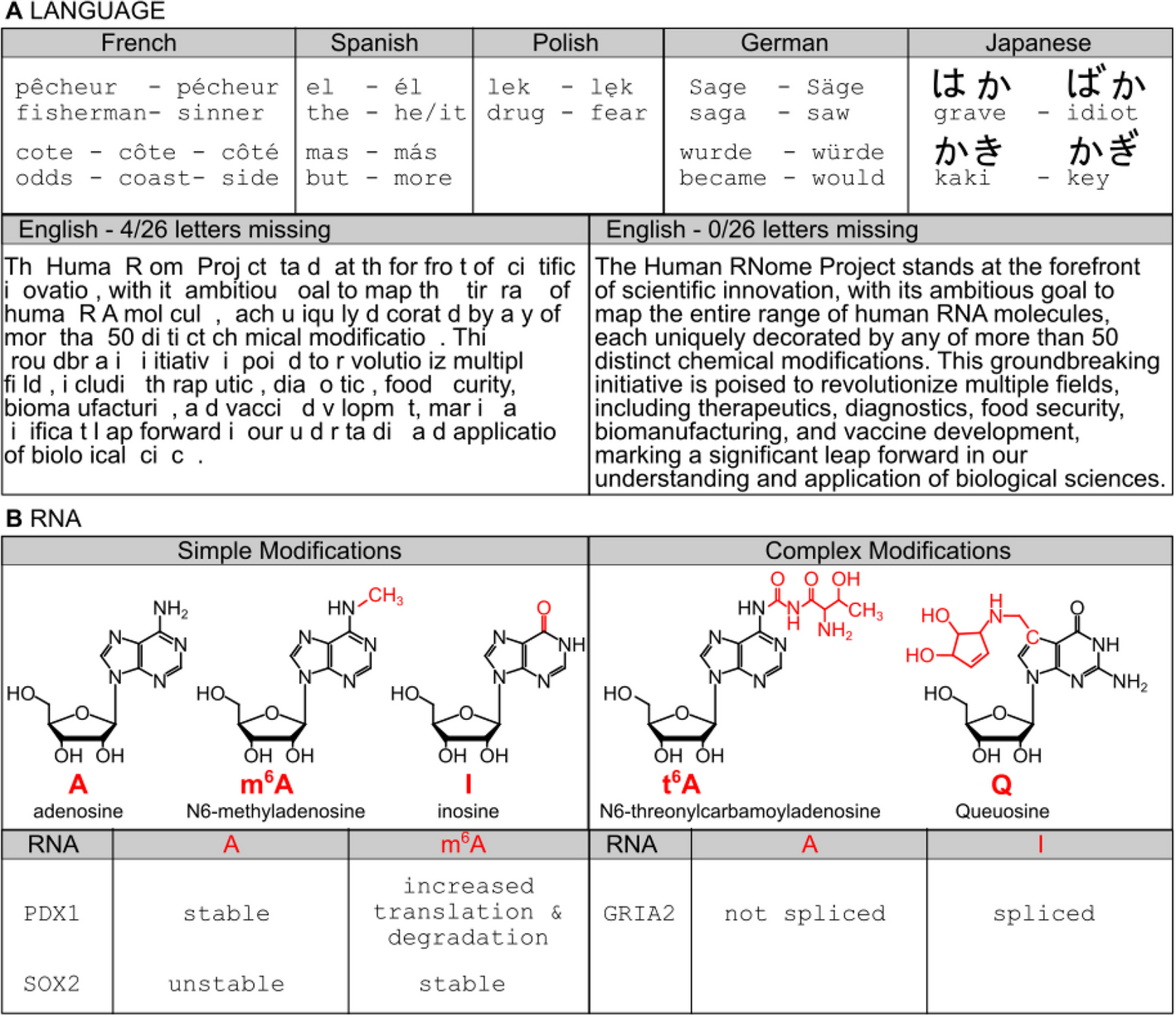
The Human RNome Project aims to ensure consistent and reproducible outcomes in RNA sequencing and modification studies by utilizing standardized cell lines maintained under uniform culture conditions. This standardized approach will facilitate meaningful comparisons across technologies and laboratories. The selected cell lines will be widely accessible, easy to maintain in culture, and highly proliferative, ensuring an adequate supply of RNA for sequencing and characterization experiments. Importantly, these cell lines will exhibit genetic stability, characterized by a well-defined genome with minimal mutations and chromosomal aberrations, to guarantee the reliability and robustness of the generated data.
To maintain genomic integrity, cell lines will be sourced from certified distributors at regular intervals and used at low passage numbers (< 8). Genetic integrity will be independently verified through DNA and cDNA sequencing, with results reported alongside direct RNA sequence data. This ensures that any genomic drift is identified and accounted for in downstream analyses.
Table 1 lists cell lines that meet these criteria. These lines have been extensively characterized by large-scale studies such as the ENCODE Project [25, 26] and the 1000 Genomes Project [17, 18]. For instance, GM12878, a cultured B-cell line from a female donor with ancestry from Northern and Western Europe, has been sequenced as part of the 1000 Genomes Project and characterized by ENCODE. IMR-90 lung fibroblasts, BJ foreskin fibroblasts, and H9 human embryonic stem cells are similarly well-characterized and available through trusted sources like Coriell, ATCC, and WiCell, which will also enforce standardized protocols for culturing and handling. Given the sensitivity of RNA to environmental factors, these standardizations are critical for ensuring data comparability. Repositories will also require users to follow consistent protocols for culturing and RNA extraction, as variations in these processes could influence RNA sequence and modification profiles.
Table 1 Cell lines for initial steps of the Human RNome Project
RNA extraction and quality control: RNA will be extracted using a guanidinium thiocyanate-based method to ensure high purity and integrity. RNA quality will be assessed by absorbance ratio (260/280 and 260/230 nm) and capillary electrophoresis (e.g., Agilent TapeStation), requiring a minimum RNA Integrity Number (RIN) of 9 for RNA extracted from cell lines (as the project advances, and RNA samples are extracted from tissues, a lower RIN threshold such as 8 may be necessary). Aliquots of RNA will be archived for validation and further analyses.
Initial RNA targets for sequencing: The pilot phase of the Human RNome Project will focus on sequencing transfer RNA (tRNA), ribosomal RNA (rRNA), and mRNA, with a focus on selected protein-coding transcripts. These RNA classes are ideal initial targets due to their ubiquity, existing knowledge of their modification profiles, and robust expression across cell types.
tRNA and rRNA
tRNA (~ 250 expressed isodecoders) and rRNA (5S, 5.8S, 18S, 28S) are universally expressed and highly conserved, with well-studied modification types and locations [12,13,14]. Table 2 lists examples of modifications typically found in human mRNA, tRNA, and rRNAs. Both total tRNA and rRNAs can be purified from total RNA using electrophoresis or size-exclusion chromatography [28], while affinity-based methods such as chaplet chromatography [29] or reciprocal circulating chromatography [30] can be used to enrich for specific tRNA sequences. One drawback of all RNA purification methods is co-purification of non-target RNAs due to similar size or hybridization to target RNAs. Mass spectrometric analysis of modified ribonucleosides in purified RNA must always be viewed with suspicion for modifications found in multiple forms of RNA (e.g., m6A, m5C).
Table 2 Known modifications in rRNAs and tRNAs as internal validations
Coding genes and their mRNAs
Selected protein-coding genes include ACTB, CDKN2A, ISG15, and SOD1. These genes were chosen based on their known association with diseases, moderate to high expression levels, relatively short transcript lengths (~ 1 kb), and known modifications. For example, SOD1 is associated with amyotrophic lateral sclerosis [31], while ACTB is widely expressed and associated with dystonia (Table 3).
Table 3 Protein-coding genes selected as representative RNAs to begin direct RNA sequencing
Coding RNA enrichment methods: To detect low-abundance modifications, enriched RNA samples are critical. Initial poly-A RNA enrichment can be achieved using oligo-dT kits from various vendors [33]. For specific RNAs, biotinylated antisense oligonucleotides allow ~ fivefold enrichment [34], while microbead-based antisense oligos are claimed to achieve a 100,000-fold enrichment [35]. DNA nanoswitches offer another option, with ~ 75% recovery and purities exceeding 99.8% for RNA ranging from 22 to 400 nts [36].
Future goals
Short-term
1.
Standardized RNA extraction using guanidinium thiocyanate.
2.
Enrichment of test RNAs using antisense-based methods.
3.
Mass spectrometry-based direct RNA-seq for short-read identification of modifications and nanopore sequencing for long-read sequencing and modification mapping.
Medium-term
1.
Sequence transcriptomes from cell sorting-enriched samples of defined cell types.
2.
Compare data with existing programs (e.g., GTEx).
3.
Expand sequencing to include different cell types and tissues from individuals of all ages and ethnicities.
Long-term
1.
Sequence RNAs from specific subcellular regions (e.g., nucleus, cytoplasm, mitochondria).
2.
Integrate single-cell transcriptomic and subcellular data.
Source molecular resources and standards
The Human RNome Project relies on robust molecular resources and chemical standards to develop and validate sequencing and mass spectrometry (MS) technologies. These resources encompass synthetic and native RNA standards, as well as their building blocks, such as ribonucleosides, ribonucleotide triphosphates (NTPs), and oligoribonucleotides. High-quality standards are essential for ensuring accurate analysis of RNA modifications, their chemistry, and their precise locations within RNA molecules.
Chemical standards
Chemical standards are indispensable for training and validating analytical methods before analyzing native RNA samples. They ensure reproducibility, correct identification of RNA modifications, and calibration of detection systems. Standards are summarized in Fig. 2 and include the following.
Fig. 2
Overview of types of chemical standards needed for the Human RNome Project
Ribonucleosides and dinucleotide caps
Chemical standards for individual ribonucleosides are essential for characterizing RNA modifications and quantifying their abundance. Approximately 90 ribonucleoside standards are commercially available, with additional variants synthesized by academic laboratories. Comprehensive lists of vendors are provided on the RNome website [33], while PubChem offers detailed vendor information and links to chemical resources. Prices for these standards range from $20 to $1500 per milligram, with custom synthesis for rare modifications costing between $10,000 and $20,000. For qualitative analysis, 1 mg of a standard is typically sufficient. For quantitative analysis, we recommend assessing the purity of the standard by quantitative NMR prior to preparing calibration solutions for, as an example, LC–MS analysis. Despite the availability of over 90 modified ribonucleosides, many human-specific RNA modifications remain inaccessible as commercial standards. Furthermore, the chemical stability (shelf life) of ribonucleosides is not well-documented. For example, m1A undergoes Dimroth rearrangement to m6A during RNA processing and storage in aqueous solution [37, 38] highlighting the need for further research into ribonucleoside stability.
Ribonucleotide triphosphates
Ribonucleotide triphosphates (NTPs) are essential for in vitro transcription to synthesize RNA molecules longer than 20 nucleotides with defined modification profiles. Canonical NTPs are widely available from commercial sources, including isotopically labeled variants, while modified NTPs for specific ribonucleosides can also be obtained. However, these modified NTPs require rigorous verification of their chemical identity and purity, typically through techniques such as thin-layer chromatography (TLC) or LC–MS [39, 40]. In vitro transcription allows random, but not site-specific incorporation of modified NTPs [41].
Synthetic oligonucleotides and phosphoramidites
Site-specifically labeled RNA oligonucleotides, ranging from 5 to > 60 nucleotides, are essential for training nanopore base callers and validating LC–MS methods. Solid-phase chemical synthesis is commonly used to produce labeled oligonucleotides and vendors typically provide mass spectra to confirm the overall product length, failure sequences, and impurities. However, comprehensive validation, such as mass spectrometric sequence verification and ribonucleoside LC–MS for modification identification, is rarely included but essential for robust validation. To ensure accuracy, researchers must advocate for detailed validation data, including MS sequence validation and ribonucleoside-specific quantification, alongside the standard mass spectra provided by vendors. Despite these advancements, the site-specific incorporation of modifications into long RNA sequences (> 60 nucleotides) remains a significant challenge [42]. Current approaches, which involve combining chemical synthesis, transcription, and ligation, are labor-intensive, low yielding, and not easily scalable. New approaches to long RNA synthesis are needed to facilitate the generation of site-specifically modified RNAs that mimic biological molecules.
Future goals
Short-term
1.
Stability data for modified ribonucleosides is scarce, highlighting the need for systematic studies on shelf life.
Medium-term
1.
Consistent preparation, validation, and distribution protocols are essential to ensure data comparability over time. Quality control samples must be maintained and shipped with detailed documentation.
2.
Researchers should demand comprehensive validation data (e.g., MS/MS, sequence confirmation) from vendors to avoid errors in downstream analyses.
Long-term
1.
Sequencing and MS methods must be regularly validated using both synthetic and native standards
2.
High-quality library of modifications with comprehensive validation data and shelf-lives. Many RNA modifications lack synthetic standards, necessitating collaboration with organic chemists for their production.
Develop advanced sequencing technologies
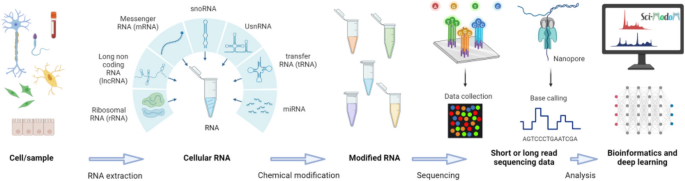
Sequencing technologies will be pivotal to the Human RNome Project, much like they were for the Human Genome Project. To evaluate the potential impact on the project, it is essential to analyze the current state and project developments over the next 5 to 10 years. The consortium has hence identified and discussed lead questions that concern the type of currently available sequencing technologies, the necessary developments in the near future, and critical quality controls.
Current state of sequencing technologies
Current methods to map modifications can be classified into direct, such as mass spectrometry or direct RNA sequencing, and indirect, which usually relies on sequencing by synthesis, wherein RNA is converted to cDNA via reverse transcriptase [16]. Both indirect and direct RNA sequencing methods require additional steps to assign modifications. This section is meant as a brief summary and not a comprehensive review of all current variations and developments (for a comprehensive review please refer to the Report by the National Academies of Sciences, Engineering and Medicine [23]).
cDNA-based sequencing
Sequencing of cDNA, acquired through reverse transcription of RNA and analyzed through Illumina (and sometimes PacBio or Nanopore), is currently the most widely used form for indirect RNA sequencing. However, it cannot directly detect non-canonical ribonucleotides. Workarounds to map modifications rely on changing the RNA or cDNA product on a molecular level (“molecular input”) and include reverse transcriptase-based error profiling, chemical or enzymatic derivatization, and modification-specific immunoprecipitation [43, 44]. Molecular input methods utilize computational algorithms that infer RNA modifications from misincorporations, gaps, or reverse transcription arrests or reverse transcription incorporation of structurally similar bases. While powerful, no single molecular input method can comprehensively identify all modifications, necessitating the use of multiple techniques on the same RNA sample.
Direct RNA sequencing
Oxford Nanopore Technologies is the only widely available platform currently providing protocols for direct, long-read sequencing of RNA molecules, eliminating the need for cDNA conversion and preserving endogenous or synthetic exogenous RNA modifications (Fig. 3) [45,46,47,48]. Advances in machine learning models have led to more accurate basecalling and lower error rates for sequencing full-length native RNA transcripts [47]. By analyzing unique changes in electrical currents from the direct RNA sequencing process, RNA modifications can be tentatively identified [48]. Identification of modified nucleotide residues can be achieved by comparison against unmodified control samples [49], with base-calling algorithms or supervised models that have been trained on data with known modifications [47, 48, 50]. The training of such models can be achieved using data from cDNA-based approaches, data from modification-free control samples [49], in vitro transcription-generated data, or data from synthetic RNAs. However, the generation and availability of such data and the lack of RNA modification standards still limit the number of modifications that can currently be confidently detected and identified. Furthermore, not all reads from direct RNA-seq correspond to full-length RNAs and challenges remain to detect RNA modifications that occur at the 5′ ends of RNA molecules. To overcome these barriers, researchers are actively developing “molecular input” approaches—such as introducing chemical or enzymatic treatments which change the RNA molecule—to amplify or clarify the signals associated with RNA modifications [51].
Fig. 3
Overview of the sequencing workflow that will allow end-to-end sequencing of RNA including its modifications
Mass spectrometry (MS)
Mass spectrometry (MS)-based RNA sequencing is an essential complement to these efforts as a means to chemically identify and accurately quantify specific modifications [52,53,54,55]. Unlike the chemically nonspecific interpretation of electrical signals in nanopore sequencing, MS-based sequencing involves high mass accuracy (i.e., exact molecular weight) determinations of modification fragments that allow structural identification of the modification, its location in the RNA sequence at single-nucleotide resolution, and its abundance in the population of RNA sequences. While MS sequencing requires larger quantities of RNA than NGS or nanopore sequencing, advances in sensitivity have moved the application from more abundant non-coding RNAs to mRNAs [55,56,57,58]. The major limitation of MS-based RNA-seq is the short fragment size needed for accurate MS analysis, typically 10–60 nt in length depending upon the mass resolution of the instrument [55]. This precludes mapping modifications in long native RNA molecules, as can be achieved with nanopore. MS-based RNA sequencing and nanopore sequencing are thus complementary tools for RNome analysis.
Quality control: ensuring the accuracy of modification-aware sequencing and analysis
The accuracy of epitranscriptomic analysis is determined by the combined impact of errors introduced during experimental procedures and data processing. To ensure high-quality data, experimental design must include an adequate number of replicates, sufficient sequencing depth, and the incorporation of both positive and negative controls. Method-specific data analysis should employ robust statistical frameworks to evaluate the significance of signals at specific sites, accounting for sample size, signal strength, and their relevance within the broader context of all samples, including replicates and controls. Given the diversity of current modification mapping methods, it is challenging to recommend a universal set of parameters for experimental design and data analysis. Therefore, we outline guidelines based on general principles in the following sections.
Conventional sequencing errors and “molecular input” errors
Base-calling accuracy in Illumina sequencing data typically has an error rate of 0.1–0.5% per nucleotide residue, while nanopore sequencing has only recently reduced its error rates to the single-digit range. While these error rates are not typically a major concern for conventional RNA sequencing, they become critical when using molecular input methods that depend on errors for mapping modifications, as these methods can introduce artifact-based errors, such as false positives and false negatives. To ensure data validity and reliability, it is essential to include a sufficient number of both biological and technical replicates, as well as adequate sequencing depth to optimize the signal-to-noise ratio. The significance of a detected signal is further strengthened by comparisons with positive and negative controls, ideally including at least one of each that represents a “gold standard” or ground truth.
Data interpretation
Quality control (QC) parameters are essential at multiple levels, including raw data (e.g., fastq files used for downstream analysis) and the analytical pipelines used for mapping modified residues. For raw data, QC criteria can often follow established standards for the respective sequencing technology, such as a Q-score > 30 for Illumina sequencing. The thresholds, however, may vary depending on whether short-read or long-read sequencing technologies are employed. Beyond this, a second layer of QC is needed to evaluate the performance of molecular input methods, which introduce their own characteristic errors. A third layer of QC pertains to computational analysis, assessing the reliability of data interpretation across different epitranscriptomics mapping protocols and pipelines. In some cases, it may be valuable to integrate these QC layers into aggregated error rates or composite metrics that encompass both molecular and computational aspects.
To advance the field, it is imperative to establish a universally accepted set of QC parameters for benchmarking methods. Equally important is the determination of standardized threshold values for these parameters, which could become mandatory for the Human RNome Project. The diversity of existing technologies, as well as those that will emerge during the project, complicates the establishment of universal QC criteria at the raw data level. However, any method must undergo rigorous validation before being deemed suitable for modification calling.
Validation should involve the creation of models evaluated with metrics such as receiver operating characteristic (ROC) curves, area under the curve (AUC), sensitivity (true positive rate), and specificity (true negative rate). Particular attention must be given to minimizing false positive and false negative rates, as these directly impact the reliability of modification detection. Another critical input parameter for these models is an accurate estimate of the expected number of residues for a given modification, as this will influence thresholds for modification calling. Such an integrative and standardized approach to QC will ensure robust and reliable results across diverse epitranscriptomic applications.
Establishing clear guidelines for reporting QC metrics in publications and data repositories is essential for fostering reproducibility and confidence in results. Comprehensive reporting of raw data quality, molecular input performance, and computational reliability will enable consistent practices across studies. Such transparency not only ensures accountability but also facilitates meta-analyses and comparisons, accelerating progress in the field.
Vision 2025: strategic steps for the next decade
Advancing modification-aware RNA sequencing on an international scale requires both organizational and technical developments. One of the greatest challenges will be achieving consensus within the field on a mandatory set of QC parameters and, even more challenging, establishing universally applicable threshold values. As highlighted earlier, in addition to maintaining a continuously updated overview of methodologies, the field must identify techniques that either deliver the highest throughput with minimal error rates or enable precise quantification of modification levels at specific RNA sites. With these considerations in mind, we outline the following ongoing and future objectives for the Human RNome Project.
Future goals
Short-term
1.
Continue developing NGS, nanopore, and MS technologies to (a) expand the repertoire of modifications for NGS and nanopore by developing and refining chemical derivatization methods; (b) expand training datasets and algorithms for nanopore; and (c) increase the sensitivity, LC resolution, and data processing algorithms for MS-based sequencing.
2.
Integrate orthogonal technologies (e.g., combinations of methods providing different molecular inputs or alternate sequencing technologies) to confirm RNA modifications with high confidence on native RNAs.
3.
Develop and implement robust quality control (QC) protocols for NGS, nanopore, and MS to (a) minimize artifacts, (b) increase statistical power, (c) increase sequencing depth, and (d) assure inter-laboratory consistency.
4.
Lay the groundwork for scaling and throughput: (a) multiplexing MS-based sequencing; (b) automation of sequencing library preparation, sample analysis, data processing, and data mining; and (c) inter-laboratory validation.
5.
Create user groups to develop, implement, and cross-validate RNA-seq methods. Begin developing or adapting websites and databases for public access to protocols and RNA-seq datasets. Engage international funding bodies to support research and development.
Medium-term
1.
Develop automated systems for RNA extraction, size- or sequence-based RNA purification, library preparation, sequencing, data processing, and data analysis.
2.
Develop and refine computational methods: (a) algorithms to interpret raw sequencing data, distinguish true modification signals from noise, and quantify modifications; (b) standardize modification-calling pipelines with open datasets; and (c) develop rigorous benchmarks to ensure reproducibility.
3.
Expand scale of sequencing efforts: Prioritize high-throughput, automated solutions to handle increasing data demands; integrate methods with lower error rates and reliable quantification into streamlined workflows.
4.
Expand RNA-seq analyses using cell and RNA targets identified in section I. Apply improved workflows to diverse cell types and RNA populations to create comprehensive modification maps.
Long-term
1.
Develop new sequencing technologies: (a) design new nanopore pore systems, (b) develop RNA-customized MS ionization, fragmentation, and detection hardware; (c) innovate platforms capable of directly sequencing full-length RNA molecules with single-base resolution and error rates < 0.1%.
2.
Continue developing AI and automation technologies: Design AI-driven base-calling algorithms for real-time error correction and precise modification detection.
3.
Expand RNA-seq databases and integrate across databases.
4.
Expand application of RNA-seq technologies: (a) cells beyond those initially identified as standards for the Human RNome Project (Section I); (b) tissues from animal models; and (c) human clinical samples.
Guidelines for data analysis, formatting, and storage
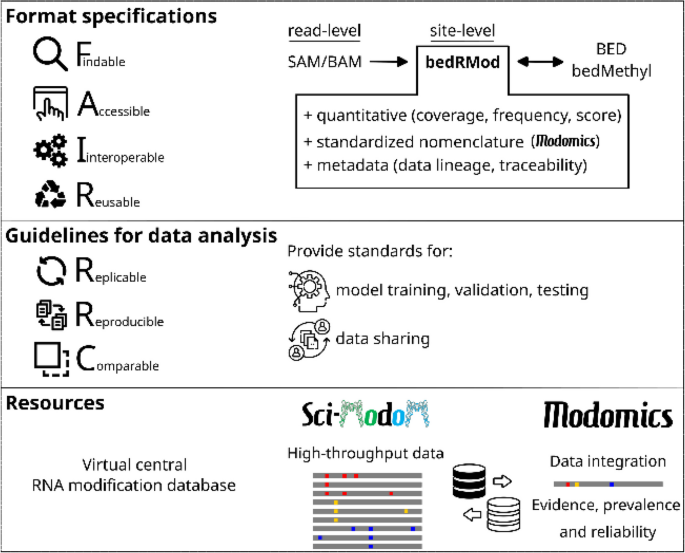
A tremendous amount of the epitranscriptome sequencing data generated in the last few years has, on the whole, remained unused, because of limited data accessibility, poor findability and reusability. Addressing these gaps could significantly enhance the utility and impact of these data. In this section, we propose FAIR guidelines [59] for data format specifications, model training standards, and protocols for recording and sharing information related to RNA sequences and modifications, applicable to both indirect and nanopore direct RNA sequencing (Fig. 4).
Fig. 4
Data handling to ensure long-term and reproducible usage of the data acquired for the Human RNome Project
Data format specifications and nomenclature
The identity, position, and frequency of RNA modifications are derived from large volumes of raw data, typically mapped reads. These analyses depend on method-specific technological expertise, which can vary significantly across approaches. Raw data alone are often not practical when only site-specific modification information is required. Moreover, this information has historically been disseminated through a range of incompatible formats, governed by varying standards, and often accompanied by limited access or incomplete metadata. These challenges have hindered reproducibility and the ability to compare results across studies.
While data formats for raw sequencing data are well-established, no such standardization exists for modification information derived from these data. At a minimum, site-specific RNA modification data should be reported in a straightforward format and include:
1.
A standardized naming convention for the modification type.
2.
Stoichiometric information, such as the percentage or frequency of the modification.
3.
Depth of coverage for the modification site.
4.
Quantitative confidence scores indicating the reliability of the modification call.
At the dataset level, metadata should be sufficiently detailed to ensure traceability, reproducibility, and reusability. This requires reliance on standardized nomenclature while maintaining flexibility to include free-text information where necessary. Some of this information has recently been incorporated into the latest SAM/BAM format specifications [60], where nucleotide residue modifications and their quality scores are recorded per-read.
At the per-site level, the recently proposed bedRMod format addresses many of these requirements [32]. This format is analogous to the ENCODE bedMethyl standard [61] and nanopore’s extended bedMethyl format [62] and compatible with the widely used BED (Browser Extensible Data) format. It was developed during the Human Genome Project [60] and approved by the GA4GH Standards Steering Committee and it integrates seamlessly with many command-line tools and genome browsers.
However, a significant barrier to the widespread adoption of the bedRMod format is its dependency on information of nucleotide residue modification from SAM/BAM files, which in turn relies on mapping algorithms. Tools to compile this data into bedRMod format at the site level remain underdeveloped, and current workflows often rely on custom algorithms to extract site-specific information into similar tabulated formats. Addressing this gap with robust, standardized tools will be essential to advancing the use and utility of bedRMod for RNA modification studies.
The RNA modification nomenclature adopted by MODOMICS [12, 13] aligns well with the requirements of the bedRMod format by providing standardized names for RNA modifications. MODOMICS uses a variety of representations, including multi-character alphanumeric codes for single and multiple sequence formats like FASTA, a one-letter Unicode-based code for sequence alignments, and a human-readable alphanumeric code for broader accessibility. Recent updates to MODOMICS have expanded its nomenclature to include synthetic residues, accommodating the growing diversity of RNA modifications in both research and practical applications [12]. This system is instrumental in ensuring compatibility across tools and datasets and holds potential as a foundation for a future standardized nomenclature under IUPAC guidelines.
Data requirements for training, validation, and testing of RNA modification
Development of RNA modification calling algorithms requires independent datasets for model training, (cross-) validation, and additional datasets for testing and benchmarking established methods. The previous sections have outlined potential biological and synthetic sources, as well as sequencing approaches, for generating these datasets. To ensure relevance, datasets may need to align with the specific focus of interest, whether tRNAs, mRNAs, or rRNAs, as these classes differ significantly in their epitranscriptomic properties and sequence characteristics.
Additionally, datasets should accurately represent the real-world distribution of modified versus unmodified nucleotides the model is expected to encounter. They must approximate the size and complexity of existing transcriptomes and include high-quality annotations for modification classes. For example, modification-free transcripts from in vitro transcription of cDNA derived from six immortalized human cell lines have been used as a robust ground-truth dataset for unmodified mRNA transcriptomes [49]. Similarly, Chan et al. [63] employed random ligation of RNA oligos with known modification statuses to construct longer transcripts with sufficient complexity in both nucleotide composition and modification density, representing another valuable resource for RNA modification research.
Towards a central RNA modification database
The Human RNome Project seeks to establish guidelines for formatting and sharing RNA sequences and modifications, while also consolidating and integrating the growing volume of high-throughput epitranscriptome data. This effort aims to enhance data accessibility, facilitate the automated discovery of datasets, and optimize data reuse. Sci-ModoM [32] introduces a novel, quantitative framework supported by the bedRMod format, advancing the adoption of FAIR data principles and fostering the use of common standards. These features position Sci-ModoM as a potential cornerstone database for RNA modifications.
Developed in synergy with MODOMICS [12, 13], Sci-ModoM complements this meta-database by offering high-throughput, high-resolution data in a standardized format. Sci-ModoM serves as a centralized platform where modifications from diverse studies can be accessed and compared, while MODOMICS provides a curated repository of RNA sequences enriched with all known modifications, along with detailed metadata on their reliability and prevalence. Together, these resources enable the visualization of modifications within RNA sequences and broaden the utility of epitranscriptome data for research, therapeutic development, and experimental applications. The integration of Sci-ModoM and MODOMICS represents a significant milestone in achieving comprehensive annotation and effective utilization of RNA modifications.
Future goals
Short-term
1.
To establish bedRMod as the format for sharing RNA modification data, and to develop the necessary infrastructure and tools to improve interoperability, and to facilitate its use by the community.
2.
To establish guidelines and minimal requirements for training, validation, testing, and sharing RNA modification data and software.
3.
To make realistic training and validation data available through Sci-ModoM to support the development of new detection methods and algorithms (cf. Future goals of section III).
Medium-term
1.
To continuously and dynamically annotate novel modifications from the large amount of data available in Sci-ModoM using MODOMICS evidence levels, reliability scores, and prevalence metrics.
2.
To enhance the interpretability of transcriptome-wide data accumulated in Sci-ModoM by contextualizing it with broader biochemical, structural, and functional information available in MODOMICS, bridging experimental findings with mechanistic insights.
3.
To provide global mirroring and public access, e.g., through collaboration with academic institutions, following the open-access model of Sci-ModoM.
Long-term
1.
To build on the synergistic development of Sci-ModoM and MODOMICS to establish a virtual central RNA modification database.
2.
To establish a standardized data flow allowing users to transition seamlessly from experimental data in Sci-ModoM to comprehensive annotations in MODOMICS.
The transformative impact of RNA science
The Human RNome Project is a bold and transformative initiative poised to revolutionize diverse sectors, including biomedicine, agriculture, data storage, and global security. By advancing RNA science, this project will deepen our understanding of RNA biology and catalyze groundbreaking innovations, delivering profound societal benefits.
Biomedicine: RNA research has made critical contributions to healthcare, particularly in understanding the biology of RNA viruses like SARS-CoV-2 and other infectious agents. These insights have accelerated the development of RNA-based therapeutics, including mRNA technologies now being adapted for applications such as influenza [64, 65] and malaria prevention [66]. Beyond infectious diseases, RNA-based therapies are transforming treatment paradigms for various conditions. Nusinersen, an antisense oligonucleotide therapy, has significantly improved outcomes for children with spinal muscular atrophy, enabling them to achieve developmental milestones [67, 68]. Inclisiran, an RNA interference-based drug, provides an effective biannual treatment for lowering LDL cholesterol, improving compliance compared to daily regimens [69, 70]. RNA-based therapies continue to advance in oncology, rare diseases, and other fields. The Human RNome Project will support this progress by improving targeting with highly accurate RNA sequences, reducing costs through the production of affordable, high-quality ribonucleotides, including modified forms, bolstering supply chains, and expanding access to RNA therapeutics.
Agriculture: Global food insecurity is a pressing issue affecting millions worldwide. In the USA alone, over 10 million children face hunger, and globally, malnutrition affected 27 million children in 2022. RNA-based technologies offer innovative solutions to address these challenges. Research shows that RNA modifications can enhance crop yields in staples like rice and potatoes [71], improving resilience and productivity. Additionally, RNA interference (RNAi) delivered via high-pressure sprays provides an effective, non-genetically engineered method to combat plant diseases [72, 73]. RNA sequencing technologies will equip plant scientists with powerful tools to improve crop productivity and combat global hunger.
Data storage: RNA presents a transformative approach to ultra-dense, efficient, and scalable data storage, capitalizing on its structural complexity and extensive chemical diversity. Unlike the binary 0,1 system traditionally used for data encoding, RNA’s repertoire of approximately 180 known ribonucleotide modifications vastly expands the encoding alphabet. While the binary system encodes 1 bit of information per symbol, RNA modifications encode approximately 7.49 bits per symbol, enabling a 649% improvement in compression efficiency.
This groundbreaking technology not only addresses the rapidly growing global demand for storage capacity, projected to surpass available resources in the coming decades, but also offers a sustainable and cost-effective alternative. By leveraging RNA’s ability to store dense information in a biochemically compact format, this innovation has the potential to revolutionize data storage while reducing the environmental and financial costs associated with conventional methods.
The Human RNome Project will be at the forefront of this innovation, establishing the necessary infrastructure to produce standard and modified ribonucleotides as foundational components for RNA-based storage. In parallel, the project will drive advancements in sequencing and synthesis technologies to ensure data integrity, reliability, and affordability. These efforts will transition RNA-based storage from theoretical concept to practical reality, opening a new frontier in data technology. By combining unparalleled storage density with innovative compression strategies, RNA-based systems promise to redefine how we store and access the world’s growing digital archives.
Pandemic and biowarfare preparedness: RNA viruses are responsible for nearly half of infectious diseases, including influenza, Ebola, hepatitis A, and COVID-19. Their high mutation rates, up to five times that of DNA viruses, make early detection and control challenging [74, 75]. The Human RNome Project will revolutionize RNA virus sequencing, enabling rapid and accurate identification of emerging pathogens. This capability will enhance global pandemic preparedness, providing the tools needed to respond swiftly to new threats. Moreover, advances in RNA sequencing will be critical for detecting engineered viruses, strengthening defenses against biowarfare, and ensuring global health and security. By enabling rapid, precise detection, the RNome Project will play a vital role in safeguarding against both natural and human-made threats.
In conclusion, the Human RNome Project will drive transformative progress across a range of fields, from health and agriculture to technology and security. By unlocking the full potential of RNA science, this initiative will deepen our understanding of fundamental biological processes and empower innovative solutions to some of humanity’s most pressing challenges. With its far-reaching applications and societal impact, the Human RNome Project promises to be a cornerstone of twenty-first-century innovation, paving the way for a healthier, more resilient future.
On a quiet morning off the coast of East Cape in the Milne Bay Province of Papua New Guinea, the island of Nuakata stirred with anticipation. Two boats gently approached the shore,…